Core Technologies
AI Framework
The main tools, orchestration layers, and runtime conventions used internally for creating and managing AI systems are described in the AI framework stack. It supports workflows from rapid prototyping to production inference by integrating standardised abstractions, internal infrastructure, and open-source libraries.
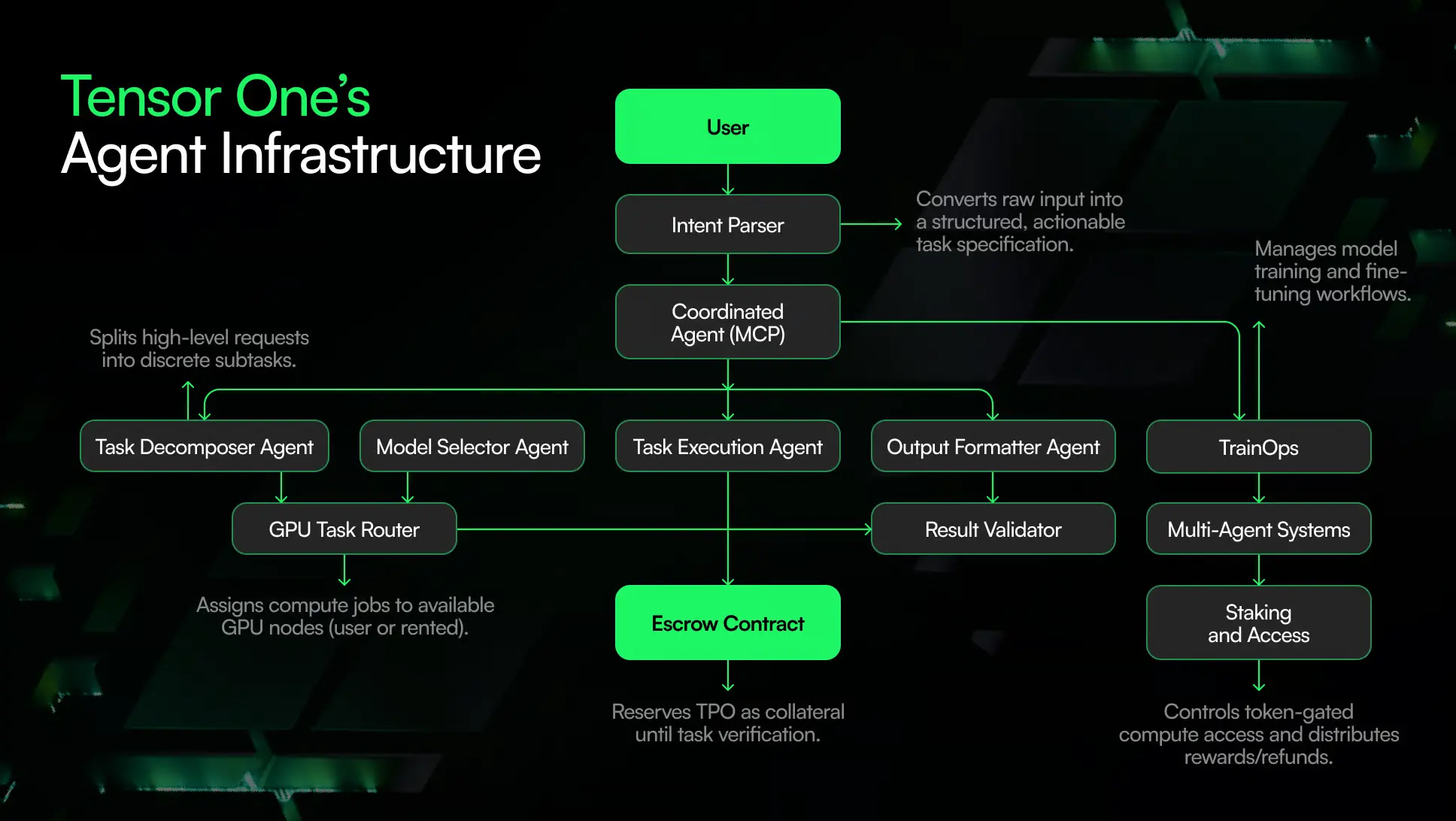
Purpose and Scope
Our AI framework is built around three core objectives:
- Standardize: Promote reusable, modular design patterns for LLM applications.
- Scale: Enable efficient execution of high-throughput inference and multi-agent workflows.
- Secure: Ensure outputs are safe, explainable, and validated.
Core Frameworks
LangChain
LangChain serves as the foundation for building LLM chains, agents, and tools. It supports:
- Prompt templating and injection
- Chaining of tools and memory modules
- Integration with vector stores like FAISS and Weaviate
Use cases: Document Q&A, prompt orchestration, function-calling workflows.
CrewAI
CrewAI provides structure for multi-agent systems, offering hierarchical control and delegation.
Key features:
- Role-based agent design
- Task routing and specialization
- Background task simulation
Internal Modules
MCP (Model Coordination Protocol)
MCP coordinates workload routing across multiple model backends and handles:
- Prioritization of GPU resources
- Failover and fallback routing
- Observability integration (logs, metrics)
It is implemented over gRPC with hooks for real-time monitoring.
Pydantic AI
Pydantic AI builds on pydantic to ensure output correctness and schema compliance. It supports:
- Parsing model outputs into typed schemas (
BaseModel.parse_llm) - Prompt input validation
- Fast error propagation for tracing
Supporting Tools
- PromptFlow: Debugger for inspecting prompt states and memory.
- Traceloop: Distributed tracing and telemetry across chain executions.
- HydraConfig: Flexible runtime configuration system for switching models, prompts, or backends.
- LLMGuard: Output sanitization layer that filters bias, jailbreaks, and unsafe content.
Common Design Patterns
- Retrieval-Augmented Generation (RAG) with hybrid search
- Stateful conversations using LangChain memory with Redis backend
- Persona-aware multi-agent flows
- Typed input schemas and structured output parsing
Deployment Targets
AI services are deployed to either TensorOne Serverless Endpoints or GPU-backed Clusters, with auto-scaling triggered by queue depth.
CI/CD pipelines utilize:
- GitHub Actions
- Docker layer caching
tensoronecli project deployfor endpoint redeployment